Non-linear regression with PyTorch and neural networks#
In this tutorial, we will explore coding neural networks to do a non-linear regression with a multi-layer perceptron.
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
import numpy as np
import matplotlib.pyplot as plt
Generate mock data#
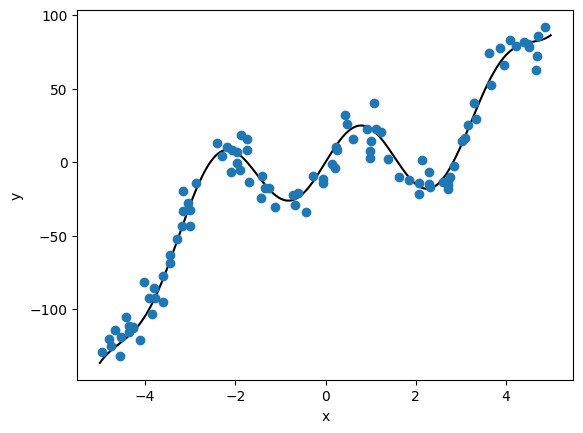
In this exercise, we generate 100 pairs of values from a non-linear function
and we add noise to a random uniform sample:
np.random.seed(42)
def ftrue(x):
""" True data function """
return(x ** 3 - x ** 2 + 25 * np.sin(2 * x))
xtrue = np.arange(-5, 5, 0.01)
ytrue = ftrue(xtrue)
n = 100
x = np.random.uniform(-5, 5, n)
y = ftrue(x) + np.random.normal(0, 10, n)
plt.plot(xtrue, ytrue, color='k')
plt.plot(x, y, 'o', color='C0')
plt.xlabel('x')
plt.ylabel('y')
Text(0, 0.5, 'y')
MLP in PyTorch#
In this section, we code a simple network using PyTorch torch.nn library.
To define a model, PyTorch requires a class definition deriving nn.Module. This class pre-defines neural networks properties and important methods.
Below, we define our neural network class. The main aspects are
the initialization/constructor function
__init__, which defines the properties of our model and parametersthe
forwardmethod which takes the model’s input and computes the corresponding prediction given the current model.
PyTorch allows flexibility in how to define neural network modules, we show below a concise implementation. Regardless, any implementation should work the same way eventually.
# number of nodes per layer (input, ..., output)
layout = [1, 10, 10, 10, 1]
Typically, our network need to take x, apply a series of Linear layer followed by an activation function until the last output layer. This corresponds to a feed foward function looking something like
z = nn.Linear(1, 10)(x)
z = nn.Linear(10, 10)(z)
z = nn.ReLU()(z)
z = nn.Linear(10, 10)(z)
z = nn.ReLU()(z)
z = nn.Linear(10, 1)(z)
All together, a common implementation would be the following:
from typing import Sequence
class MLP(nn.Module):
''' Multi-layer perceptron for non-linear regression. '''
def __init__(self, layout: Sequence[int]):
super().__init__() # initialize following nn.Module
n_input = layout[0]
n_output = layout[-1]
n_hidden = layout[1: -1]
self.sequence = torch.nn.Sequential()
# add input layer
self.sequence.add_module("input",
torch.nn.Linear(n_input, n_hidden[0]))
self.sequence.add_module(f"activation_input",
torch.nn.ReLU())
# set hidden layers
for e, (n1, n2) in enumerate(zip(n_hidden[:-1], n_hidden[1:])):
self.sequence.add_module(f"hidden_{e:d}",
torch.nn.Linear(n1, n2))
self.sequence.add_module(f"activation_{e:d}",
torch.nn.ReLU())
# set output layer
self.sequence.add_module("output",
torch.nn.Linear(n_hidden[-1], n_output))
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.sequence(x)
model = MLP(layout)
model
MLP(
(sequence): Sequential(
(input): Linear(in_features=1, out_features=10, bias=True)
(activation_input): ReLU()
(hidden_0): Linear(in_features=10, out_features=10, bias=True)
(activation_0): ReLU()
(hidden_1): Linear(in_features=10, out_features=10, bias=True)
(activation_1): ReLU()
(output): Linear(in_features=10, out_features=1, bias=True)
)
)
We can access the current parameter values of this model instance like so:
p = list(model.parameters())
p
[Parameter containing:
tensor([[ 0.5957],
[-0.2095],
[ 0.9439],
[ 0.3724],
[ 0.0083],
[ 0.7601],
[ 0.9996],
[ 0.1230],
[ 0.0193],
[-0.1383]], requires_grad=True),
Parameter containing:
tensor([ 0.8483, 0.9051, 0.3053, -0.4575, -0.6207, 0.5739, -0.9388, 0.3494,
-0.2727, -0.2968], requires_grad=True),
Parameter containing:
tensor([[-0.0815, -0.1203, 0.2260, 0.1604, -0.2505, -0.1397, -0.2555, -0.3098,
0.2177, -0.1701],
[ 0.0339, -0.2815, 0.1118, -0.1974, -0.3102, -0.1016, 0.1442, -0.1922,
0.2321, 0.2647],
[-0.2568, 0.2317, -0.1925, -0.1528, 0.2167, 0.1578, -0.1405, 0.0215,
-0.1596, -0.1999],
[-0.2609, -0.0892, 0.1190, 0.1843, -0.2448, -0.1443, 0.1279, 0.3129,
0.1593, -0.2072],
[ 0.2477, 0.0610, 0.1475, 0.1105, 0.2457, 0.1855, 0.1531, 0.1143,
0.2058, 0.1265],
[-0.1750, 0.0696, -0.0701, -0.1006, 0.2634, -0.2636, 0.0596, 0.0423,
-0.0904, 0.0137],
[-0.1992, -0.2048, -0.0184, -0.2192, -0.0618, 0.2923, 0.2422, -0.2877,
0.1879, 0.0197],
[ 0.2598, 0.2574, -0.0518, 0.2915, 0.0410, 0.1598, 0.2681, -0.1554,
-0.1318, 0.1276],
[ 0.1472, -0.2884, -0.0034, -0.0970, -0.1357, 0.0315, -0.2795, 0.1820,
0.0104, 0.0825],
[ 0.1168, -0.0154, -0.2390, 0.1218, -0.0500, -0.2797, -0.2937, 0.1958,
-0.3042, -0.0349]], requires_grad=True),
Parameter containing:
tensor([-0.0751, -0.1982, 0.2927, -0.1406, -0.1750, -0.0559, -0.0574, -0.1329,
-0.2584, -0.0128], requires_grad=True),
Parameter containing:
tensor([[ 1.8853e-01, 3.1487e-01, -1.3321e-01, 2.7611e-01, -6.5985e-02,
1.5190e-01, 2.3778e-01, -1.7344e-01, 1.8188e-01, -6.0346e-04],
[ 1.1805e-01, 2.9807e-01, 1.6034e-01, -3.1055e-01, -2.5140e-01,
2.5764e-01, -2.9676e-01, -1.4071e-01, 2.1692e-01, -9.9120e-02],
[ 1.8787e-01, 8.2359e-02, -2.6943e-01, -2.7640e-01, 1.5982e-01,
9.9762e-02, 2.9986e-01, 8.2952e-02, 2.9520e-02, 1.1230e-01],
[ 2.6853e-01, 3.0767e-01, -2.3740e-01, 3.2451e-02, 2.6745e-01,
5.1565e-02, 1.7632e-01, 9.4864e-02, 1.2595e-01, -2.2632e-01],
[ 6.6794e-02, 1.4345e-01, 1.6067e-01, 2.1540e-01, 1.8903e-01,
1.6268e-01, -1.0659e-01, 2.9245e-01, 2.2184e-01, 1.0753e-02],
[ 2.4664e-01, 1.4580e-01, 1.0861e-01, 2.2553e-01, -2.7989e-01,
2.9145e-03, 2.5426e-02, 1.3034e-01, 1.9074e-01, -2.3959e-01],
[-1.4100e-01, -7.8086e-02, -2.4486e-01, -1.6356e-01, 2.3353e-01,
-2.8770e-01, 5.2474e-02, 1.7933e-01, 1.5975e-01, 6.2671e-02],
[-2.9377e-01, 4.0539e-02, -2.9290e-01, -1.8188e-01, 8.2487e-02,
1.0687e-04, -7.5867e-02, -8.1707e-02, 3.0670e-01, -2.8326e-01],
[-2.4652e-01, 1.6804e-01, 4.8564e-02, 4.9895e-02, -1.8922e-01,
4.8270e-02, 2.0123e-01, 1.0683e-01, -2.6501e-01, 1.9162e-01],
[-8.3793e-02, 1.2565e-01, -1.1219e-02, -2.7306e-01, 2.2517e-01,
-2.0160e-01, -2.8942e-01, 1.1192e-01, 1.3327e-01, 1.0213e-01]],
requires_grad=True),
Parameter containing:
tensor([-0.2445, 0.2477, 0.0151, 0.1034, 0.1456, -0.1321, -0.1087, 0.1510,
0.2201, -0.3071], requires_grad=True),
Parameter containing:
tensor([[-0.0494, -0.0922, -0.0967, 0.2176, -0.1031, -0.0615, 0.0475, -0.1661,
0.1883, 0.0229]], requires_grad=True),
Parameter containing:
tensor([-0.1537], requires_grad=True)]
Exercise#
What are these parameters? (Hint: they are in oder of the sequence and computations in the forward method.)
Guess how the weights are initialized.
Preparing our training data#
In PyTorch, there are multiple ways to prepare a dataset for the model training. The main aspect is to convert the data into tensors which are transparently moved to GPUs if needed.
To make a standard API that works with small and large datasets, PyTorch provides two data primitives:
torch.utils.data.Datasetto store the data in a reusable format,torch.utils.data.DataLoadertakes aDatasetobject as input and returns an iterable to enable easy access to the training data (especially useful for batch training).
Dataset#
To define a Dataset object, we have to write a class deriving the latter and specify two key methods:
__len__, which tells subsequent applications how many data points there are in total (useful if you load the data by chunk); andthe
__getitem__function, which takes an index as input and outputs a corresponding (input, output) pair.
class Data(Dataset):
'''
Custom 'Dataset' object for our regression data.
Must implement these functions: __init__, __len__, and __getitem__.
'''
def __init__(self, X: np.array, Y: np.array):
self.X = torch.from_numpy(X.astype('float32'))
# self.X = torch.reshape(torch.from_numpy(X.astype('float32')), (len(X), 1))
self.Y = torch.from_numpy(Y.astype('float32'))
# self.Y = torch.reshape(torch.from_numpy(Y.astype('float32')), (len(Y), 1))
def __len__(self):
return(len(self.X))
def __getitem__(self, idx):
return(self.X[idx], self.Y[idx])
# instantiate Dataset object for current training data
d = Data(x, y)
d
<__main__.Data at 0x7fd5d01f4d90>
Let’s instanciate also the data loader (or data feeder). For this example, we will provide the data in batches of 25 random examples (out of 100).
# instantiate DataLoader
traindata = DataLoader(d, batch_size=25 , shuffle=True)
traindata
<torch.utils.data.dataloader.DataLoader at 0x7fd5d03985e0>
traindata is an iterator:
for i, data in enumerate(traindata, 0):
x_, y_ = data
print(i, "x: ", x_, "\n y:", y_)
0 x: tensor([ 0.4671, 3.8721, 3.2874, 0.1423, -1.4325, -1.2546, -0.0482, -0.0620,
4.6958, 1.3756, -1.1132, 4.6991, 0.9241, -3.1818, -2.0877, -3.8041,
-1.6910, 0.2476, 0.4270, -4.9448, 2.7513, -2.2865, 2.8518, -3.1515,
-4.0233])
y: tensor([ 25.8555, 77.5463, 40.0407, -1.0187, -24.1286, -17.4553,
-14.0970, -11.2564, 72.4186, 2.0188, -30.2676, 85.6337,
22.3660, -43.3690, -6.6115, -85.5464, -13.6547, 8.5559,
31.8135, -128.9298, -9.9971, 4.3547, -2.8406, -19.8194,
-81.2161])
1 x: tensor([ 1.0112, -1.7467, -3.7796, 3.0220, 3.0840, -2.8766, 2.7127, -0.2779,
4.6563, 4.0932, -4.4192, -2.4122, -4.7458, -4.3495, -4.5477, -3.0033,
-4.3644, 0.2007, 2.7097, 3.3244, 2.1324, 2.7224, -1.8902, -1.7482,
-1.4153])
y: tensor([ 14.4213, 15.7340, -92.5483, 14.3873, 16.6807, -14.3082,
-13.1067, -9.1593, 62.8837, 82.9752, -104.8872, 12.8990,
-124.9745, -115.2196, -132.0164, -32.7063, -111.6443, -4.2839,
-15.3508, 29.3308, 1.5792, -18.1907, -5.1677, 8.1559,
-9.5557])
2 x: tensor([ 1.0754, -0.7246, -4.7942, 4.3950, -3.0402, -3.8413, -1.3364, -3.2948,
-4.6561, -0.5985, -0.4393, -2.0786, 2.2961, 2.2901, -3.4398, 1.8423,
-3.6051, -1.9539, -1.8829, 2.6079, 1.2330, -4.2596, 3.9483, 4.5071,
-2.1907])
y: tensor([ 39.8593, -22.3093, -119.9483, 81.3993, -27.5696, -103.2141,
-17.8145, -52.4148, -114.0007, -20.8303, -33.6776, 7.9944,
-6.4008, -14.5515, -68.7726, -11.9837, -77.2336, 6.6595,
18.4182, -13.4188, 20.7272, -112.7767, 65.9028, 78.2317,
10.6050])
3 x: tensor([-4.2545, 3.6618, 0.9790, 1.6252, 0.6128, 2.3199, 2.0807, -3.9211,
-3.1660, -4.5355, 1.1185, -3.4401, -1.9576, 2.0686, 4.8689, 4.2187,
-0.6805, -3.0128, 3.6310, -4.1151, 0.9866, 0.2273, -3.5908, 4.4889,
3.1546])
y: tensor([-112.3374, 52.0719, 7.6225, -10.1584, 15.8420, -16.9126,
-21.6395, -92.3877, -33.2877, -118.4899, 22.7629, -63.0249,
-0.8871, -13.8992, 91.8363, 78.8356, -29.1518, -43.2635,
74.0932, -120.4929, 3.1146, 10.1679, -94.8232, 80.3634,
25.0627])
Note
The training set in our current example is small and training by batch is not necessary
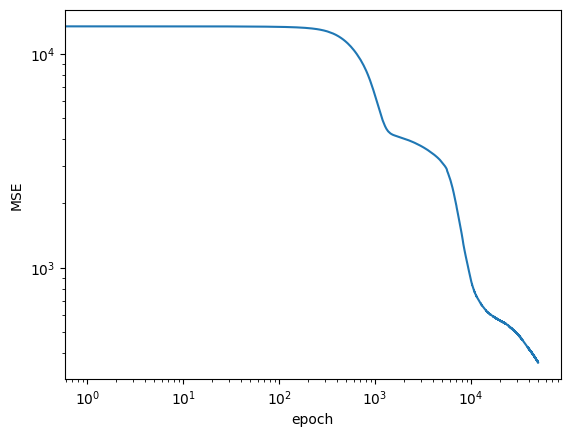
Training the model#
In many libraries, writing the training code is the most important part and varies from library to library. They also have common bricks:
the loss function: let’s take MSE here.
the optimizer: let’s take Adam (a flavor of stochastic gradient descent) with a learning rate \(10^{-4}\)
the training loop: which for many epoch, feed the data to the model, calculate the loss function, the gradient of it (backpropagation), and update the optimizer for the next iteration.
In PyTorch, this looks like the following:
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
epochs = 50_000
logs = [] # keep track
for epoch in range(0, epochs):
current_loss = 0.0
# Iterate over the batches from the DataLoader
for i, batch in enumerate(traindata):
# Get inputs
x_, y_ = batch
# reset/Zero the gradients
optimizer.zero_grad()
# Perform forward pass
# ypred = model(x_).squeeze()
ypred = model(torch.reshape(x_, (len(x_), 1))).squeeze()
# Compute loss
loss = loss_function(ypred, y_)
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
current_loss += loss.item()
# display some progress ;)
if (epoch + 1) % 2500 == 0:
print(f'Loss after epoch {epoch+1:5d}: {current_loss:.4g}')
logs.append(current_loss)
current_loss = 0.0
# Process is complete.
print('Training finished.')
Loss after epoch 2500: 3868
Loss after epoch 5000: 3111
Loss after epoch 7500: 1681
Loss after epoch 10000: 872.3
Loss after epoch 12500: 685.7
Loss after epoch 15000: 617.8
Loss after epoch 17500: 588.2
Loss after epoch 20000: 567.7
Loss after epoch 22500: 551.1
Loss after epoch 25000: 532.1
Loss after epoch 27500: 513.4
Loss after epoch 30000: 494.3
Loss after epoch 32500: 475.3
Loss after epoch 35000: 455.1
Loss after epoch 37500: 435.7
Loss after epoch 40000: 418.8
Loss after epoch 42500: 404.1
Loss after epoch 45000: 389.6
Loss after epoch 47500: 375.2
Loss after epoch 50000: 362
Training finished.
plt.loglog(logs)
plt.xlabel('epoch')
plt.ylabel('MSE')
Text(0, 0.5, 'MSE')
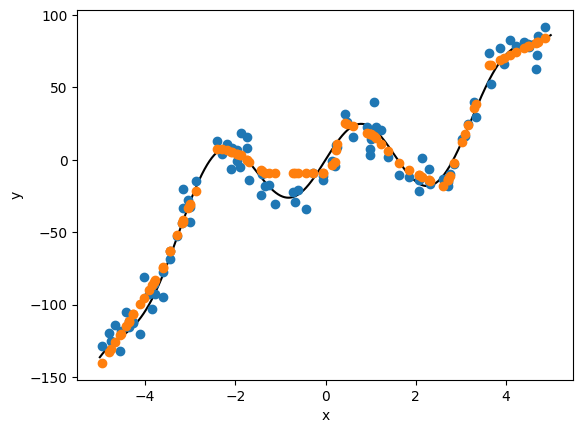
# let's check our predictions
x_ = torch.from_numpy(x.astype('float32'))
ypred = model(torch.reshape(x_, (len(x_), 1))).squeeze().cpu().detach().numpy()
plt.plot(xtrue, ytrue, color='k')
plt.plot(x, y, 'o', color='C0')
plt.plot(x, ypred, 'o', color='C1')
plt.xlabel('x')
plt.ylabel('y')
Text(0, 0.5, 'y')
Exercise Explore the model’s behavior
Make sure you understand the various lines of code.
Change the model layout, activations, optimizer, etc.
Change the mini-batch configuration. e.g. All data at once
Run the model when you change something and discuss notable differences. Explain what your observations. (If you do not see anything, that could happen. Explain why)
Exercise Revisit the XOR problem with pytorch.
# create data
X = torch.Tensor([[0., 0.],
[0., 1.],
[1., 0.],
[1., 1.]])
y = torch.Tensor([0., 1., 1., 0.]).reshape(X.shape[0], 1)
Show code cell source
class XOR(nn.Module):
def __init__(self):
super(XOR, self).__init__()
self.linear = nn.Linear(2, 2)
self.activation = nn.Sigmoid()
self.linear2 = nn.Linear(2, 1)
def forward(self, input):
x = self.linear(input)
sig = self.activation(x)
yh = self.linear2(sig)
return yh
xor_network = XOR()
epochs = 1000
mseloss = nn.MSELoss()
optimizer = torch.optim.AdamW(xor_network.parameters(), lr = 0.03)
logs = []
for epoch in range(epochs):
yhat = xor_network.forward(X)
loss = mseloss(yhat, y)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if (epoch + 1) % 250 == 0:
print(f'Loss after epoch {epoch+1:5d}: {loss:.4g}')
logs.append(loss.item())
Loss after epoch 250: 0.1782
Loss after epoch 500: 0.1694
Loss after epoch 750: 0.1679
Loss after epoch 1000: 0.1647
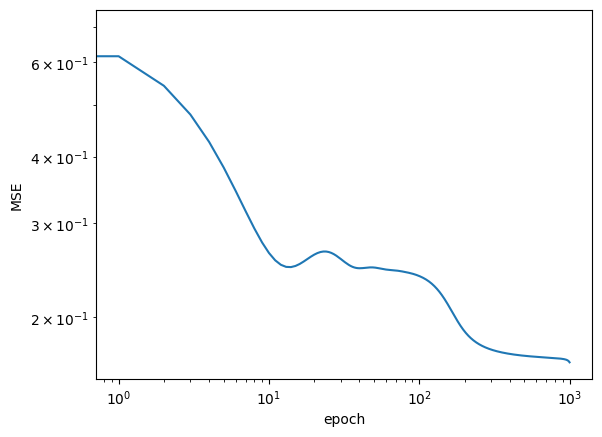
plt.loglog(logs)
plt.xlabel('epoch')
plt.ylabel('MSE')
Text(0, 0.5, 'MSE')
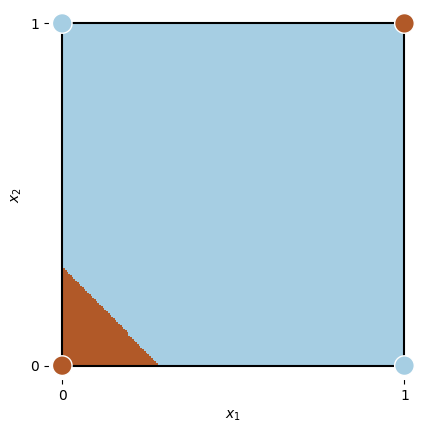
def plot_data(xor_data, ax=None):
if ax is None:
ax = plt.gca()
ax.plot([0, 1, 1, 0, 0], [0, 0, 1, 1, 0], color='k')
ax.scatter(xor_data[:, 0], xor_data[:, 1], c=xor_data[:, 2],
cmap='Paired_r', s=200, zorder=10, edgecolors='w')
ax.set_xlabel('$x_1$')
ax.set_ylabel('$x_2$')
plt.setp(ax.spines.values(), color='w')
ax.set_xticks([0, 1], [0, 1])
ax.set_yticks([0, 1], [0, 1])
X_, Y_ = np.meshgrid(np.linspace(0, 1, 200), np.linspace(0, 1, 200))
x1 = torch.from_numpy(np.c_[X_.ravel().astype('float32'), Y_.ravel().astype('float32')])
Z = np.round(xor_network(x1).squeeze().cpu().detach().numpy())
xor_data = np.array([[0, 0, 0],
[1, 0, 1],
[0, 1, 1],
[1, 1, 0]])
ax = plt.subplot(111, aspect='equal')
plot_data(xor_data, ax)
Z = Z.reshape(X_.shape)
plt.pcolormesh(X_, Y_, Z, cmap=plt.cm.Paired_r)
plt.xlim(-0.04, 1.04)
plt.ylim(-0.04, 1.04);